
Анализ контента Netflix
ВВЕДЕНИЕ
Проект посвящен анализу контента Netflix, основанного на датасете, содержащем информацию о фильмах и телешоу. В рамках анализа рассматриваются различные параметры, такие как возрастной рейтинг, жанры, длительность, страны производства и др.
Визуализация включает в себя круговые и гистограммные диаграммы, которые помогают раскрыть тренды в производстве контента по годам, популярности жанров и типам контента (фильмы vs телешоу).
ИСПОЛЬЗОВАНИЕ БИБЛИОТЕК
1.Pandas — для работы с данными и их предобработки. 2.Matplotlib & Seaborn — для создания графиков и визуализаций. 3.Plotly — для создания интерактивных графиков, таких как круговые диаграммы. 4.WordCloud — для генерации облаков слов для визуализации самых популярных жанров.
ОБРАБОТКА ДАННЫХ
- Удаление и замена пропусков: Мы заполнили пропуски в таких столбцах, как rating, country, date_added, и duration, а также удалили столбцы с ненужной информацией (например, director и cast). - Создание новых признаков: Добавлен новый столбец target_ages, который отображает целевую аудиторию контента, основанный на значениях rating. - Преобразование типов данных: Типы данных для столбцов type и target_ages были изменены на категориальные.
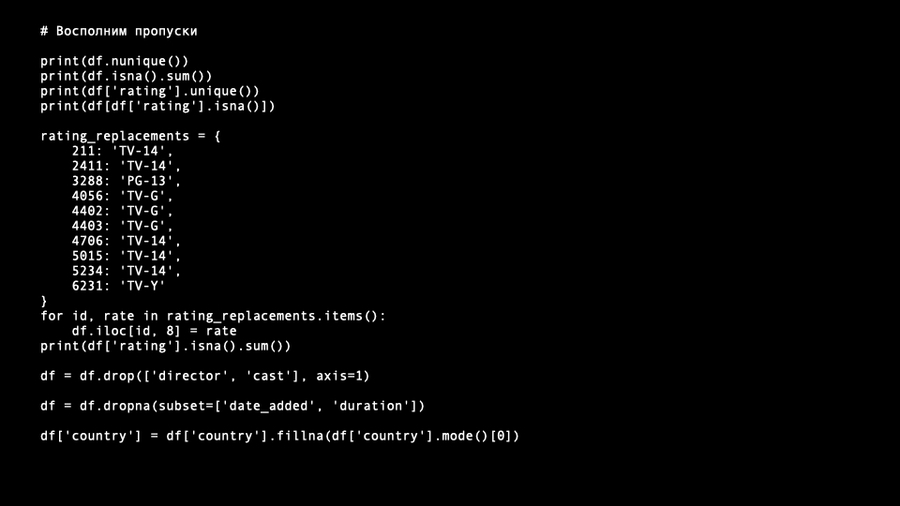
ВИЗУАЛИЗАЦИЯ
Круговая диаграмма для отображения распределения контента по типам (Movie vs TV Show). - Гистограмма для отображения топ-5 стран по количеству контента. - Кольцевая диаграмма для демонстрации распределения контента по целевой аудитории. - Облако слов для визуализации популярных жанров. - Гексагональная плотность для анализа зависимости между годами выпуска и длиной первого жанра.
ДАТАСЕТ И БЛОКНОТ



